



A karakterfelismerő szoftverek eszméletlenül drágák. A leghíresebb Abbyy Fine Reader például 40'000 ft. Ha van Office 2007 vagy 2010 installálva a gépeden, akkor van ingyen karakterfelismerő szoftvered is! Csak eddig nem tudtál róla... :D
Az Office 2007 és 2010 programcsomag része az Office OneNote jegyzetkészítő és -kezelő program, amivel egy helyen gyűjthetjük össze a fontos gondolatainkat, kereshetünk rá, és megoszthatjuk az eredményt másokkal is. Én speciel (és szerintem sokan mások) nem nagyon használták ezt a programot. Gondoltam egyet és kipróbáltam. Nem állapot, hogy folgalja a helyet, itt porosodik a meghajtón és még egyszer sem futtattam. Mindig csak a Vör'd meg az Ek'szel... Egy érdekes OCR funkciót fedeztem föl benne:
Bármilyen képről, amin van szöveges rész és megnyitjuk a programban "lelophatjuk" a szöveget. Legyen szó egy képernyőfotóról, amit a PrintScreen gomb megnyomásával készítettünk, vagy egy a szkennerünkből beolvasott képről vagy egy pdf dokumentumról, amiből nem tudjuk kimásolni a szöveget.
1. Nyissunk egy új jegyzetet ( Fájl>Létrehozás>Lap. ) Hívjunk be egy képet a programba. Ezt többféleképpen tehetjük:
- Beszúrás>Kép>Fájlból....
- Beszúrás>Kép>Képolvasóból vagy fényképezőből, ha szkennelni akarunk.
- Printscreen gombbal készítünk egy képernyőfotót, majd a programban Ctrl+V gombbal beillesztjük.
- Beszúrás>Képernyőrész kivágása - nagyon pöpec kis funkció, csak kijelölünk valamit a képernyőnkön, és az már ott is van a programban képként. Itt egyből a szöveget is kijelölhetjük a képernyőről, lényegében az előző PrintScreen-es megoldás továbbfejlesztett változata (ahol ugye a teljes képernyőről készíthetünk csak képet mindenestül).
- Ha egy pdf doksit akarunk felismertetni, akkor a pdfolvasó programunkban menjünk a nyomtatás menüpontra, és ott válasszuk a nyomtatók közül a "Küldés a OneNote programba" pontot!
.png)
2. Ezután Jobbklikk a képre>Képbeli szöveg kereshetővé tétele>Válasszuk ki a szöveg nyelvét!
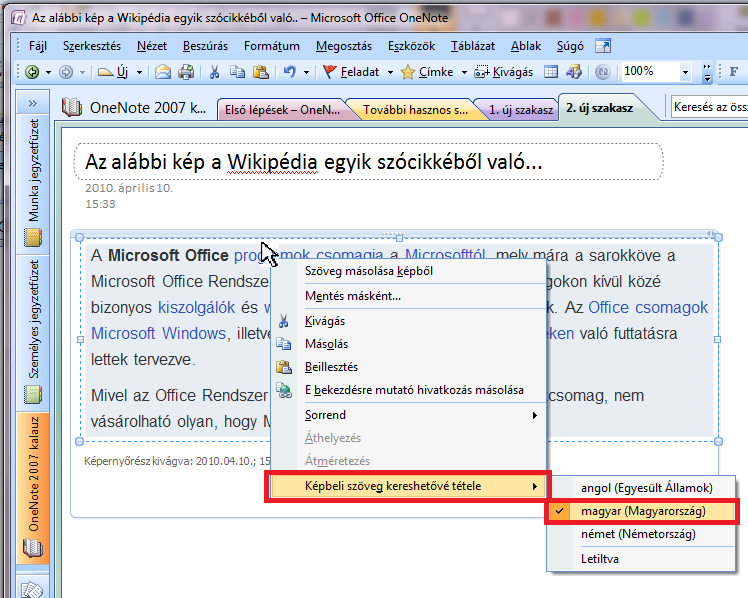
3. Végül másoljuk ki a "Jobbklikk>Szöveg másolása" menüponttal a szöveget, majd illesszük be a nekünk kellő helyre, szövegszerkesztőbe stb...
Tapasztalatok: Minél vastagabb a képen lévő karakter, annál nagyobb bizonyossággal ismeri fel a program azokat. Például egy beszkennelt képnél egész szép eredményeket érhetünk el, viszont a fenti szövegben van 1 db hiba. Nem sok! Íme a kép és a felismert szöveg:
 -
-
És a felismert szöveg:A Microsoft Office programok csomagja a Microsofttól, mely mára a sarokköve a Microsoft Office Rendszernek, melybe a Microsoft Office csomagokon kívül közé bizonyos kiszolgálók és webalapú szolgáatások is beletartoznak Az Office csomagok Microsoft Windows, illetve Apple Macintosh operációs rendszereken való futtatásra lettek tervezve. Mivel az Office Rendszer nem egy egyszerű termék vagy termékcsomag, nem vásárolható olyan, hogy Microsoft Office Rendszer
10 komment
Címkék: ingyen kép office program pdf numlock szkenner holmes azonosítás scanner képfelismerés digitalizál ocr karakterfelismerés recognita onenote fine reader beolvas
Ajánlott bejegyzések:




A bejegyzés trackback címe:
Kommentek:
A hozzászólások a vonatkozó jogszabályok értelmében felhasználói tartalomnak minősülnek, értük a szolgáltatás technikai üzemeltetője semmilyen felelősséget nem vállal, azokat nem ellenőrzi. Kifogás esetén forduljon a blog szerkesztőjéhez. Részletek a Felhasználási feltételekben és az adatvédelmi tájékoztatóban.

Kontárblog · http://kontar.blog.hu/ 2010.04.10. 16:00:01
köszi!

numlockholmes 2010.04.10. 16:13:57
Celtic 2010.10.10. 15:58:24

házibölcs 2010.11.07. 12:52:00
ilyennevmegnincsremelem 2011.07.18. 20:38:45
Rbu 2012.02.21. 16:46:37
Köszönöm a tippet, nagyon jól működik a program, de sajnos nekem az ékezeteket nem ismeri fel. Van erre valami megoldás?
Az a baj, hogy egyenként átírni nagyon hosszú idő, mert 100 oldal körüli szöveget kell így átalakítanom. (Igen, tudom, begépelni még hosszabb lenne...)
Kérlek segítsetek!
Köszönöm, R
Revolutionist 2013.12.18. 20:50:27
numlockholmes 2013.12.18. 20:54:43
Revolutionist 2013.12.19. 23:26:28
Közben utánaolvasgattam szakfórumokban és ismert a jelenség. Ez egy bug. Rá kellett telepíteni legalább a 2-es, de mégjobb ha a 3-as szervízcsomagot, melyek korrigálják; és valóban: onnantól már működött is a dolog szépen... (már meg is csináltam vele sikerrel gyorsan tegnap a szöveget, amit akartam) Köszi...